Transcribed:
Max Tegmark (@tegmark):
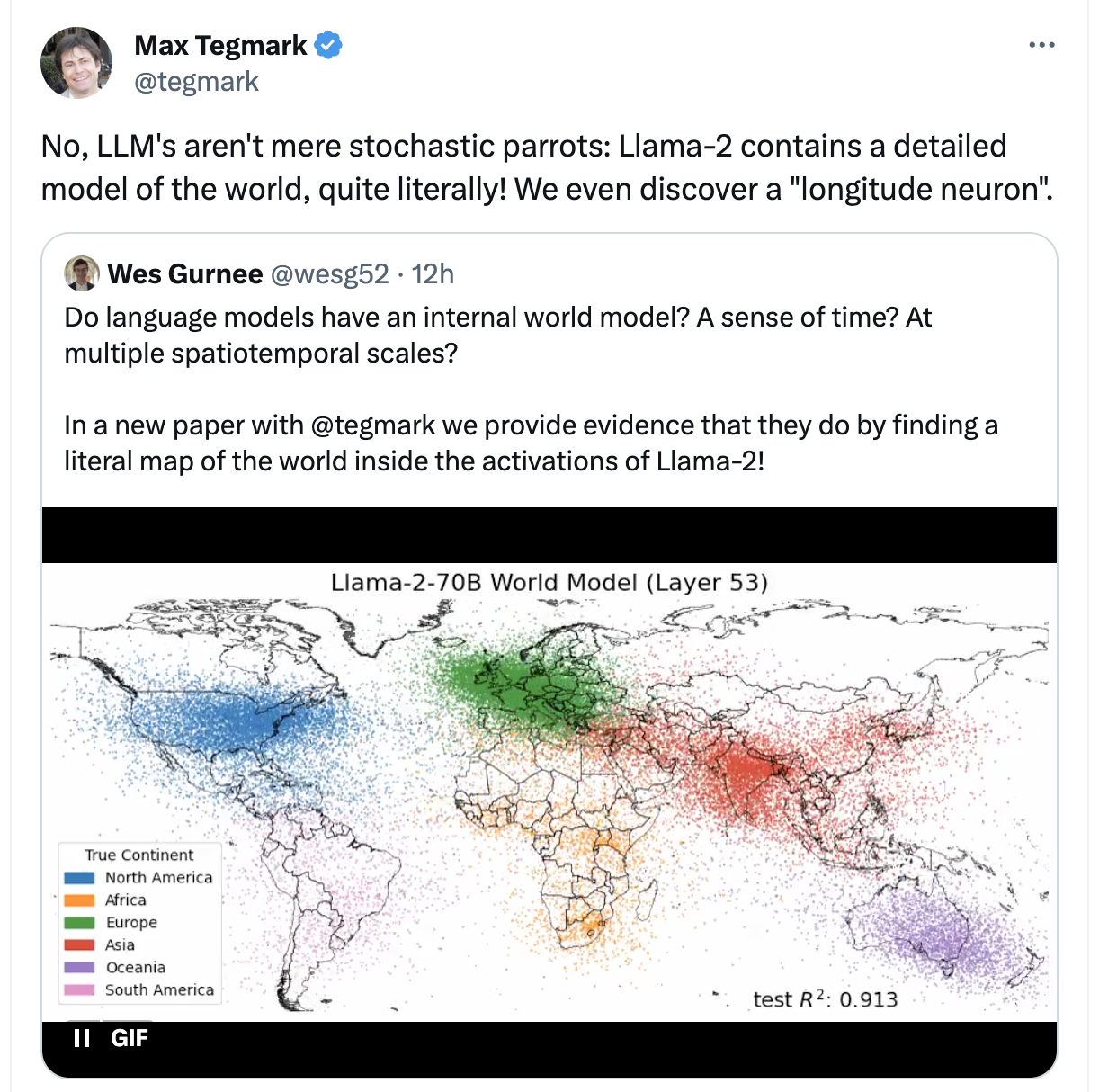
No, LLM's aren't mere stochastic parrots: Llama-2 contains a detailed model of the world, quite literally! We even discover a "longitude neuron"Wes Gurnee (@wesg52):
Do language models have an internal world model? A sense of time? At multiple spatiotemporal scales?
In a new paper with @tegmark we provide evidence that they do by finding a literal map of the world inside the activations of Llama-2! [image with colorful dots on a map]
With this dastardly deliberate simplification of what it means to have a world model, we've been struck a mortal blow in our skepticism towards LLMs; we have no choice but to convert surely!
(*) Asterisk:
Not an actual literal map, what they really mean to say is that they've trained "linear probes" (it's own mini-model) on the activation layers, for a bunch of inputs, and minimizing loss for latitude and longitude (and/or time, blah blah).
And yes from the activations you can get a fuzzy distribution of lat,long on a map, and yes they've been able to isolated individual "neurons" that seem to correlate in activation with latitude and longitude. (frankly not being able to find one would have been surprising to me, this doesn't mean LLM's aren't just big statistical machines, in this case being trained with data containing literal lat,long tuples for cities in particular)
It's a neat visualization and result but it is sort of comically missing the point
Bonus sneers from @emilymbender:
- You know what's most striking about this graphic? It's not that mentions of people/cities/etc from different continents cluster together in terms of word co-occurrences. It's just how sparse the data from the Global South are. -- Also, no, that's not what "world model" means if you're talking about the relevance of world models to language understanding. (source)
- "We can overlay it on a map" != "world model" (source)
I.... so. damn you, I looked.
this says
their code does... a lot of things with that input data. including filling some in and conveniently removing "small" towns and some states and eliminating duplicates[1] and other shit
a very quick glance at some of the input data:
cool. so. we have high-precision data with actual coordinates and well-defined information. as the input. to the mash-things-together-into-a-proximates-slurry machine.
and then on prompting the slurry with questions about "hey where is Wyoming", it can provide a rough answer.
amazing.
[1] - whoops forgot the footnote. how about that Washingon in every state, huh? sure is a good thing the US doesn't have lots of reused names!
Wow. I was kinda tongue-in-cheeking it there, because I genuinely thought I was misinterpreting/over-simplifying the OP, but they really are trying to sell "it didn't discard this data we explicitly fed it" as some kind of big deal.
I was expecting this to be more like them discovering that regional dialects exist or soemthing dumb-but-not-that-dumb.
promptfans, making grandiose badfaith claims that turn out so not-even-wrong it entirely moves the goalposts on the argument? nevarrrr
these fucking people
we need a run of @dgerard@awful.systems’s “it can’t be that stupid, you must be explaining it wrong” stickers but with the ChatGPT logo instead of the bitcoin one
also how can we talk shit about LLMs when computation was impossible until they were invented?
15-ish years ago, I was doing a lot of principal component analysis and multi-dimensional scaling. A standard exercise in that area is to take distances between cities, like the lengths of airline flight paths, and reconstruct a map. If only I'd thought to claim that to be a world model!
Fucking Christ, that hurt to read.