Hello! Let me first clarify, this is for a personal project, based on an idea I always use to learn all kinds of things: personal finance tracking.
The DB model I typically use looks something like this:
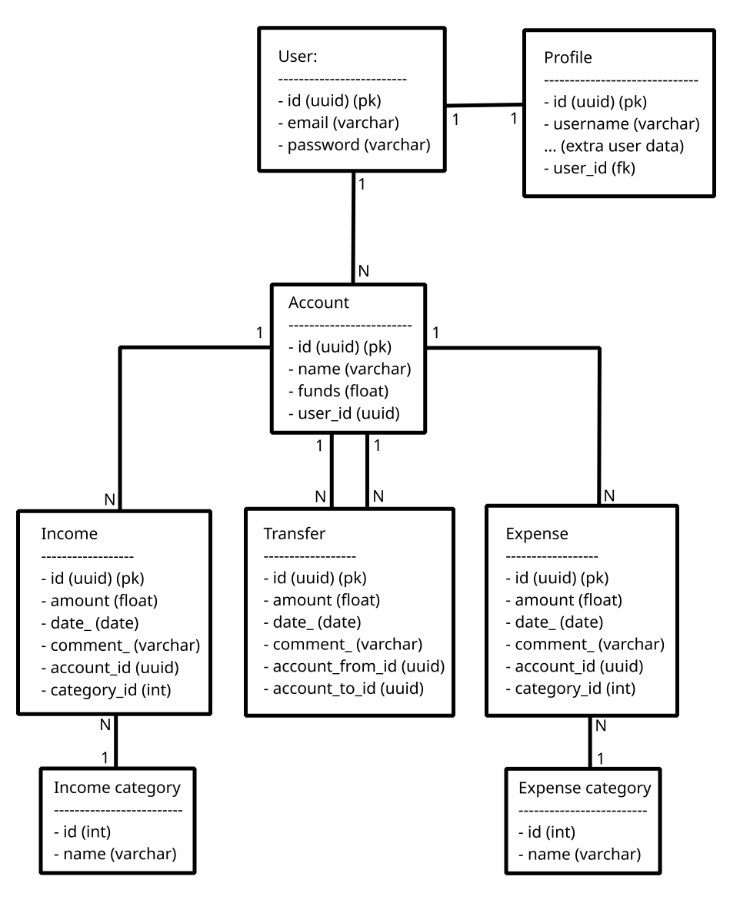
Initially, I made the decision to separate incomes, expenses and transfers into separate tables, which makes sense to me, according to the way I learned DB normalization.
But I was wondering if there is any benefit in somehow mixing the expense and income tables (since they are almost identical, and any code around these is always almost identical), or even all 3 (expense, income and transfer). Maybe it is more convenient to have the data modeled like this this for an API, but for BI or analytics, a different format would be more convenient? How would such format look like? Or maybe this would be better for BI and analytics, but for an API it's more convenient to have something different?
A while ago at a previous job, an experienced software architect once suggested, for a transactional system, to separate the transactional DB from a historical DB, and continuously migrate the data differences through ETL's. I have always thought that idea is pretty interesting, so I wonder if it makes sense to try in my little personal project.
If it was you, how would you model personal finance tracking? Is there something you think I may be missing, or that I should look into for DB modeling?
(Note: I intentionally do not track loans / investments, or at least I have not tried to integrate it for the sake of simplicity, and I have no interest in trying YET.)

Beautiful! I only reply just now because I JUST got it working. This is exactly what I was looking for, thank you sooo much :) I'm keeping both approaches in a lil template project I have, and definitely checking Serilog next!