Reddthat Announcements
691 readers
1 users here now
Main Announcements related to Reddthat.
- For all support relating to Reddthat, please go to !community@reddthat.com
founded 1 year ago
MODERATORS
1
Hello! It seems you have made it to our donation post.
Thankyou
We created Reddthat for the purposes of creating a community, that can be run by the community. We did not want it to be something that is moderated, administered and funded by 1 or 2 people.
Current Recurring Donators on OpenCollective:
Current Total Amazing People on OpenCollective:
Background
In one of very first posts titled "Welcome one and all" we talked about what our short term and long term goals are.
In 7 days since starting, we have already federated with over 700 difference instances, have 24 different communities and over 250 users that have contributed over 550 comments. So I think we've definitely achieved our short term goals, and I thought this was going to take closer to 3 months to get these types of numbers!
We would like to first off thank everyone for being here, subscribing to our communities and calling Reddthat home!
Donation Links (Updated 2024-08)
- Open Collective: https://opencollective.com/reddthat
- (best for recurring donations)
- Stripe 3% + $0.3
- Ko-Fi: https://ko-fi.com/reddthat
- (best for once off donations)
- Stripe 3% + $0.3
- 5% on all recurring (Unless I pay them $8/month for 0% fee)
- Crypto:
- XMR Directly:
4286pC9NxdyTo5Y3Z9Yr9NN1PoRUE3aXnBMW5TeKuSzPHh6eYB6HTZk7W9wmAfPqJR1j684WNRkcHiP9TwhvMoBrUD9PSt3 - BTC Directly:
bc1q8md5gfdr55rn9zh3a30n6vtlktxgg5w4stvvas - Crypto Mining Pool: Pool Info
Host: donate.reddthat.com, Port: 3333
Current Plans:
- Create our own production Lemmy builds with cherry picked commits to help with the long load times.
- In April 2025 we are renewing our server hosting for the next 12 months. At that point in time we will evaluate if we can scale down to a more cost effective instance.
Annual Costings:
Our current costs are
- Domain: 15 Euro (~$25 AUD)
- Server: $897.60 Usd (~$1365 AUD)
- EU Server: 39 Euro (~$64 AUD)
- Wasabi Object Storage: $72 Usd (~$111 AUD)
- Total: ~1565 AUD per year (~$130.42/month)
That's our goal. That is the number we need to achieve in funding to keep us going for another year.
Cheers,
Tiff
PS. Thank you to our donators! Your names will forever be remembered by me: Last updated on 2024-08-08
Current Recurring Gods (🌟)
- Nankeru (🌟)
- souperk (🌟)
- Incognito (x3 🌟🌟🌟)
- ThiccBathtub (🌟)
- Bryan (🌟)
- Guest (x2 🌟🌟)
- Ashley (🌟)
- Alex (🌟)
- MentallyExhausted (🌟)
Once Off Heroes
- Guest(s) x13
- souperk
- MonsiuerPatEBrown
- Patrick x4
- Stimmed
- MrShankles
- RIPSync
- Alexander
- muffin
- Dave_r
- Ed
- djsaskdja
- hit_the_rails
2
3
Hello. It is I, Tiff. I am not dead contrary to my lack of Reddthat updates 😅 !
It's been a fun few months since our last update. We've been mainlining those beta releases, found critical performance issues before they made it into the wider Lemmyverse and helped the rest of the Lemmyverse update from Postgres 15 to 16 as part of the updates for Lemmy versions 0.19.4 and 0.19.5!
Thank-you to everyone who helped out in the matrix admin rooms as well as others who have made improvements which will allow us to streamline the setup for all future upgrades.
And a huge thank you to everyone who has stuck around as a Reddthat user too! Without you all this little corner of the world wouldn't have been possible. I havn't been as active as I should be for Reddthat, moderating, diagnosing issues and helping other admins has been taking the majority of my Reddthat allocated time. Creating these "monthly" updates should... be monthly at least! so I'll attempt start posting them monthly, even if nothing is really happening!
High CPU Usages / Long Load Times
Unfortunately you may have noticed some longer page load times with Reddthat, but we are not alone! These issues are with Lemmy as a whole! Since the 0.19.x releases many people have talked about Lemmy having an increase in CPU usage, and they have the monitoring to prove it too. On average there was a 20% increase and for those who have single user instance this was a significant increase. Especially when people were using a raspberry pi or some other small form factor device to run their instance.
This increase was one of the many reasons why our server migrations were required a couple months ago. There is good news believe it or not! We found the issue with the long page load times, and helped the developers find the solution! -
This change looks like it will be merged within the next couple days. Once we've done our own testing, we will backport the commit and start creating our own Lemmy 'version'. Any backporting will be met with scrutiny and I will only cherry-pick the bare minimum to ensure we never get into a situation where we are required to use the beta releases. Stability is one of my core beliefs and ensuring we all have a great time!
Donation Drive
We need some recurring donations!
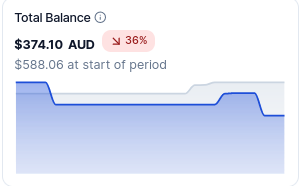
We currently have $374.10 and our operating costs have slowly been creeping up over the course of the last few months. Especially with the current currency conversions. The current deficit is $74. Even with the amazing 12 current users we will run out of money in 5 months. That's January next year! We need another 15 users to donate $5/month and we'd be breaking even. That's 1 coffee a month.
If you are financially able please see the sidebar for donation options, go to our funding post , or go directly to our Open Collective and signup for recurring donations!
Our finances are viewable to all and you can see the latest expense here: https://opencollective.com/reddthat/expenses/213722
- OVH Server (Main Server) - $119.42 AUD
- Wasabi S3 (Image Hosting) - $16.85 AUD
- Scaleway Server (LemmyWorld Proxy) - $6.62 AUD
Scaleway
Unfortunately until Lemmy optimises their activity sending we still need a proxy in EU, and I havn't found any server that is cheaper than €3.99. If you know of something with 1GB RAM with an IPv4 thats less than that let me know. The good news is that Lemmy.ml is currently testing their new sending capabilities so it's possible that we will be able to eventually remove the server in the next year or so. The biggest cost in scaleway is actually the IPv4. The server itself is less than €1.50 so if lemmy.world had IPv6 we could in theory save €1.50/m. In saying all this, that saving per month is not a lot of money!
Wasabi
Wasabi S3 is also one of those interesting items where in theory it should only be USD$7, but in reality they are charging us closer to USD$11. They charge a premium for any storage that is deleted before 30 days, as they are meant to be an "archive" instead of a hot storage system.
This means that all images that are deleted before 30 days incur a cost. Over the last 30 days that has amounted to 305GB! So while we don't get charged for outbound traffic, we are still paying more than the USD$7 per month.
We've already tried setting the pictrs caching to auto-delete the thumbnails after 30 days rather than the default 7 days, but people still upload and delete files, and close our their accounts and delete everything. I expect this to happen and want people to be able to delete their content if they wish.
OVH Server
When I migrated the server in April we were having database issues. As such we purchased a server with more memory (ram) than the size of the database, which is the general idea when sizing a database. Memory: 32 GB. Unfortunately I was thinking on a purely technical level rather than what we could realistically afford and now we are paying the price. Literally. (I also forgot it was in USD not AUD :| )
Again, having the extra ram gives us the ability to host our other frontends, trial new features, and ensure we are going to be online incase there are other issues. Eventually we will also increase our Lemmy applications from 1 to 2 and this extra headroom will facilitate this.
Donate your CPU! (Trialing)
If you are unable to donate money that is okay too and here is another option! You can donate your CPU power instead to help us mine crypto coins, anonymously! This is a new initiative we are trialing. We have setup a P2Pool at: https://donate.reddthat.com. More information about joining the mining pool can be found there. The general idea is: download a mining program, enter in our pool details, start mining, when our pool finds a "block", we'll get paid.
I've been testing this myself as an option of the past month as a "side hustle" on some laptops. Over the past 30 days I managed to make $5. Which is not terrible if we can scale it out. If it doesn't takes off, that's fine too!
I understand some people will be hesitant for any of the many reasons that exist against crypto, but any option to help us pay our server bills and allow people to donate in an anonymous way is always a boon for me.
Conclusion
These Lemmy bugs have been causing a headache for me in diagnosing and finding solutions. With the upcoming 0.19.6 release I hope that we can put this behind us and Reddthat will be better for it.
Again, thank you all for sticking around in our times of instabilities, posting, commenting and engaging in thoughtful communications.
You are all amazing.
Cheers,
Tiff

4
5
April is here and we're still enjoying our little corner of the lemmy-verse! This post is quite late for our April announcement as my chocolate coma has only now subsided
Donations
Due to some recent huge donations recently on our Ko-Fi we decided to migrate our database from our previous big server to a dedicated database server. The idea behind this move was to allow our database to respond faster with a faster CPU. It was a 3.5GHz cpu rather than what we had which was a 3.0GHz. This, as we know, did not pan out as we expected.After that fell through we have now migrated everything to 1 huge VPS in a completely different hosting company (OVH).
Since the last update I used the donations towards setting up an EU proxy to filter out down votes & spam as a way to try and respond faster to allow us to catch up. We've purchased the new VPS from OVH (which came out of the Ko-Fi money), & did the test of the separate database server in our previous hosting company.
Our Donations as of (7th of April):
- Ko-Fi: $280.00
- OpenCollective: $691.55 (of that 54.86 is pending payment)
Threads Federation
Straight off the bat, I'd like to say thank you for those voicing your opinions on the Thread federation post. While we had more people who were opposed to federation and have since deleted their accounts or moved communities because of the uncertainty, I left the thread pinned for over a week as I wanted to make sure that everyone could respond and have a general consensus. Many people bought great points forward, and we have decided to block Threads. The reasoning behind blocking them boils down to:
- Enforced one-way communication, allowing threads users to post in our communities without being able to respond to comments
- Known lack of Moderation which would allow for abuse
These two factors alone make it a simple decision on my part. If they allowed for comments on the post to make it back to a threads user then I probably would not explicitly block them. We are an open-first instance and I still stand by that. But when you have a history of abusive users, lack of moderation and actively ensure your users cannot conduct a conversation which by definition would be 2 way. That is enough to tip the scales in my book.
Decision: We will block Threads.net starting immediately.
Overview of what we've been tackling over the past 4 weeks
In the past month we've:
- Re-configured our database to ensure it could accept activities as fast as possible (twice!)
- Attempted to move all lemmy apps to a separate server to allow the database to have full use of our resources
- Purchased an absurd amount of cpus for a month to give everything a lot of cpu to play with
- Setup a haproxy with a lua-script in Amsterdam to filter out all 'bad' requests
- Worked with the LW Infra team to help test the Amsterdam proxy
- Rebuilt custom docker containers for added logging
- Optimised our nginx proxies
- Investigated the relationship between network latency and response times
- Figured out the maximum 3r/s rate of activities and notified the Lemmy Admin matrix channel, created bug reports etc.
- Migrated our 3 servers from one hosting company to 1 big server at another company this post
This has been a wild ride and I want to say thanks to everyone who's stuck with us, reached out to think of ideas, or send me a donation with a beautiful message.
The 500 mile problem (Why it's happening for LemmyWorld & Reddthat)
There are a few causes of this and why it effects Reddthat and a very small number of other instances but the main one is network latency. The distance between Australia (where Reddthat is hosted) and Europe/Americas is approximately 200-300ms. That means the current 'maximum' number of requests that a Lemmy instance can generate is approximate 3 requests per second. This assumes a few things such as responding instantly but is a good guideline.
Fortunately for the lemmy-verse, most of the instances that everyone can join are centralised to the EU/US areas which have very low latency. The network distance between Paris and Amsterdam is about 10ms. This means any instances that exist in close proximity can have an order of magnitude of activities generated before they lag behind. It goes from 3r/s to 100r/s
- Servers in EU<->EU can generate between 50-100r/s without lagging
- Servers in EU<->US can generate between 10-12r/s without lagging
- Servers in EU<->AU can generate between 2-3r/s without lagging
Already we have a practical maximum of 100r/s that an instance can generate before everyone on planet earth lags behind.
Currently (as of writing) Lemmy needs to process every activity sequentially. This ensures consistency between votes, edits, comments, etc. Allowing activities to be received out-of-order brings a huge amount of complexity which everyone is trying to solve to allow for all of us (Reddthat et al.) to no longer start lagging. There is a huge discussion on the git issue tracker of Lemmy if you wish to see how it is progressing.
As I said previously this assumes we respond in near real-time with no processing time. In reality, no one does, and there are a heap of reasons because of that. The biggest culprit of blocking in the activity threads I have found (and I could be wrong) is/was the metadata enrichment when new posts are added. So you get a nice Title, Subtitle and an image for all the links you add. Recent logs show it blocks adding post activities from anywhere between 1s to 10+ seconds! Since 0.19.4-beta.2 (which we are running as of this post) this no longer happens so for all new posts we will no longer have a 5-10s wait time. You might not have image displayed immediately when a Link is submitted, but it will still be enriched within a few seconds. Unfortunately this is only 1 piece of the puzzel and does not solve the issue. Out of the previous 24hours ~90% of all recieved activities are related to votes. Posts are in the single percentage, a rounding error.
This heading is in reference to the 500 miles email.
Requests here mean Lemmy "Activities", which are likes, posts, edits, comments, etc.
So ... are we okay now?
It is a boring answer but we wait and enjoy what the rest of the fediverse has to offer. This (now) only affects votes between LemmyWorld to Reddthat. All communities on Reddthat are successfully federating to all external parties so your comments and votes are being seen throughout the fediverse. There are still plenty of users in the fediverse who enjoy the content we create, who interact with us and are pleasant human beings. This only affects votes because of our forcing federation crawler which automatically syncs all LW posts and comments. We've been "up-to-date" for over 2 weeks now.
It is unfortunate that we are the ones to be the most affected. It's always a lot more fun being on the outside looking in, thinking about what they are dealing with and theorising solutions. Knowing my fellow Lemmy.nz and aussie.zone were affected by these issues really cemented the network latency issue and was a brilliant light bulb moment. I've had some hard nights recently trying to manage my life and looking into the problems that are effecting Reddthat. If I was dealing with these issues in isolation I'm not sure I would have come to these conclusions, so thank you our amazing Admin Team!
New versions means new features (Local Communities & Videos)
As we've updated to a beta version of 0.19.4 to get the metadata patches, we've already found bugs in Lemmy (or regressions) and you will notice if you use Jerboa as a client. Unfortunately, rolling back isn't advisable and as such we'll try and get the issues resolved so Jerboa can work.
We now have ability to change and create any community to be "Local Only".
With the migration comes support for Video uploads, Limited to under 20MB and 10000 frames (~6 minutes)! I suggest if you want to shared video links to tag it with [Video] as it seems videos on some clients don't always show it correctly.
Thoughts
Everyday I strive to learn about new things, and it has certainly been a learning experience! I started Reddthat with knowing enough of alternate technologies, but nearly nothing of rust nor postgres. 😅
We've found possibly a crucial bug in the foundation of Lemmy which hinders federation, workarounds, and found not all VPS providers are the same. I explained the issues in the hosting migration post. Learnt a lot about postgres and tested postgres v15 to v16 upgrade processes so everyone who uses the lemmy-ansible repository can benefit.
I'm looking forward to a relaxing April compared to the hectic March but I foresee some issues relating to the 0.19.4 release, which was meant to be released in the next week or so. 🤷
Cheers,
Tiff
PS. Since Lemmy version 0.19 you can block an instance yourself without requiring us to defederate via going to your Profile, clicking Blocks, and entering in the instance you wish to be blocked.
Fun Graphs:
Instance Response Times:


Data Transfers:

6
7
8
9
10
11
Recently beehaw has been hung out to dry with Open Collective dissolving their Foundation which was their hosted collective. Basically, the company that was holding onto all of beehaw's money, will no longer accept donations, and will close. You can read more in their alarmingly titled post: EMERGENCY ANNOUNCEMENT: Open Collective Foundation is dissolving, and Beehaw needs your help
While this does not affect us, it certainly could have been us. I hope the Beehaw admins are doing okay and manage to get their money back. From what I've seen it should be easy to zero-out your collective, but "closure" and "no longer taking donations" make for a stressful time.
Again, Reddthat isn't affected by this but it does point out that we are currently at the behest of one company (person?) from winning the powerball or just running away with the donations.
Fees
Upon investigating our financials we are actually getting stung on fees quite often. Forgive me if I go on a rant here, skip below for the donation links if you don't want to read about the ins and outs. OpenCollective uses Stripe, which take 3% + $0.30 per transaction. Thats pretty much an industry standard. 3% + 0.30. Occasionally it's 3% + 0.25 depending on the payment provider Stripe uses internally. What I didn't realise is that Open Collective also pre-fills the donation form. This defaults to 15.00%. So in reality when I have set the donation to be $10, you end up paying $11.50. $1.50 goes to Open Collective, and then Stripe takes $0.48 in transaction fees. Then, when I get reimbursed for the server payments, Stripe takes another payment fee, because our Hosted Collective also has to pay a transfer fee. (Between you and me, I'm not sure why that is when we are both in Australia... and inter-bank transactions are free). So of that $11.50 out of your pocket, $1.50 goes to Open Collective, Stripe takes $0.48, then at the end of the month I lose $0.56 per expense! We have 11 donators so and 3 expenses per month, which works out to be another $0.15 per donator. So at the end of the day, that $11.50 becomes $9.37. A total difference of $2.13 per donator per month.
As I was being completely transparent I broke these down to 3 different transactions. The Server, the extra ram, and our object storage. Clearly I can save $1.12/m by bundling all the transactions, but that is not ideal. In the past 3 months we have paid $26.83 in payment transaction fees.
After learning this information, anyone who has recurring donations setup should check if the would like to continue giving 15% to Open Collective or not, or pass that extra 15% straight to Reddthat instead!
So to help with this outcome we are going to start diversifying and promoting alternatives to Open Collective as well as attempting to publish, maybe a specific page which I can update like /donate. But for the moment we will update our sidebar and main funding page.
Donation Links
From now on we will be using the following services.
- Ko-Fi: https://ko-fi.com/reddthat
- (best for once off donations)
- 0% on once-off donations
- 5% on all recurring (Unless I pay them $8/month for 0% fee)
- Open Collective: https://opencollective.com/reddthat
- (best for recurring donations)
- Stripe 3% + $0.3 (+ $0.58 Expense fee/month)
- Crypto:
- XMR Directly:
4286pC9NxdyTo5Y3Z9Yr9NN1PoRUE3aXnBMW5TeKuSzPHh6eYB6HTZk7W9wmAfPqJR1j684WNRkcHiP9TwhvMoBrUD9PSt3 - BTC Directly:
bc1q8md5gfdr55rn9zh3a30n6vtlktxgg5w4stvvas
I'm looking into Librepay as well but it looks like I will need to setup stripe myself, if I can do that in a safe way (for me and you) then I'll add that too.
Next Steps
From now on I'll be bundling all expenses for the month into one "Expense" on Open Collective to minimise fees as that is where most of the current funding is. I'll also do my best to do a quarterly budget report with expenditures and a sum of any OpenCollective/Kofi/Crypto/etc we have.
Thank you all for sticking around!
Tiff

12
13
14
15
16
Hello Everyone, I would like to wish everyone a happy New Year period where we've decided as a human race to stop working and start enjoying spending copious amounts of money on loved ones, items for ourselves, or just relishing the time to relax and recuperate.
Whatever your desired state of mind while the New Year period is we at Reddthat hope you enjoy it!
Community Funding
First up, I'd like to thank our dedicated community members who keep the lights on. Knowing that together we are creating a little home on the internet pleases me to no end. Thankyou!
A special mention to our first time contributors as well. Welcome to Reddthat: Ashley & Guest!
If you are new to Reddthat and have not seen our OpenCollective page it is available over here. All transactions and expenses are completely transparent. If you donate and leave your name you'll eventually find your way into our main funding post over here
User Statistics
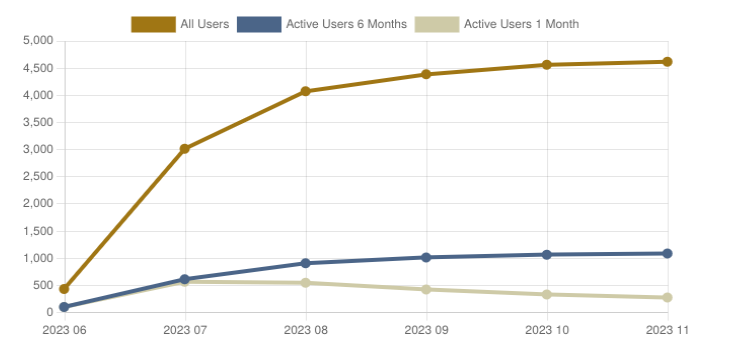
As some of you might know, the Lemmy-verse is not populated as it once was back when people were thinking of a max-exodus. But do not be dismayed! These graphs show the dedication of our userbase rather than a dying platform.
These lines are replicated across all of the biggest instances not just our own. If you are interested checkout Fediverse Observer who I borrowed these graphs from. Thank-you!
I'm proud to know that over 250 people are using the services we provide & I hope you are enjoying it too!
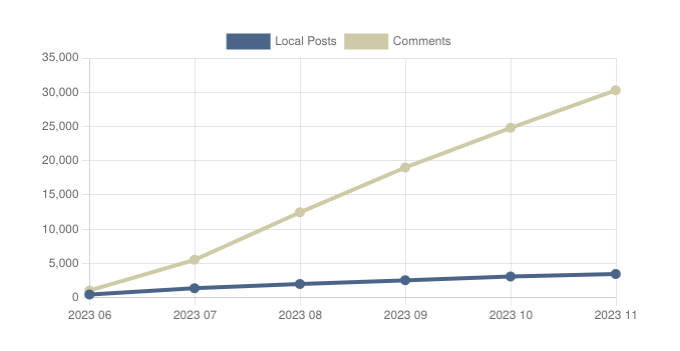
A rise of close to 5000 comments MoM goes to show that we have a healthy amount of users in the fediverse who are actively interacting and communicating.
Users
Posts/Comments
Server Stability (Maintenance Windows) & Future Plans
The server has been rock solid the past month(s) since the last update. Except for 2 unscheduled outages, one when our hosting provider restarted the underlying host. This was during their weekly maintenance window so I can't be completely mad at them and was due to them finishing migrating everything between the old host we were on.
For everyone's information, the maintenance windows are: (UTC)
- Friday nights -- 22:00 to 01:00
- Tuesday afternoons -- 12:00 to 16:00
The majority of the time you will never see downtime during these periods but if you do happen to see high load times or error pages, that will be the cause. Due to the nature of this, I also perform maintenance during these periods such as system updates.
Dedicated server?
Our eventual plan was to always purchase a dedicated server with a beefy CPU & NVMe drive to enable us to do 3 things:
- Provide fast database queries to reduce latency and give a snappy experience
- On-demand support for encoding videos to allow you to post video memes
- Allow for growth to over 10k active users per month
Black Friday/Cyber Monday not withstanding, dedicated servers cost on average A$150-200/m. You can get better deals with other providers but for budgeting wise it is a good range.
With the bots leaving and some people deciding federated platforms were not right for them, the decisions are answered for us. While it would be good to provide a slightly faster experience, or be able to withstand over 10k active users per day, we are not there yet.
Our current solutions have growing room for the foreseeable future and until we outgrow our server it seems prudent not willingly waste money.
We have always been community funded and the trust that you have given us to make the best call for our future is something that I will not squander.
Lemmy v0.19 & Pictrs v0.5 features (coming soon)
The new version of Lemmy is getting closer and closer to being ready for fediverse-wide adoption for everyone to use (as in next week!). As previously stated in our October update there will be teething issues for those with 2FA but we are here for you.
Pictrs (the app which processes all the pictures/memes/gifs/videos) is due to release 0.5 soon as well. Which brings with it new database support, specifically postgres. This is the same database which Lemmy runs on, which means all Lemmy server admins will be able to run multiple pictrs instances to provide faster images, handle greater concurrent uploads, and if all goes well, less transcoding of supported videos.
Once the Lemmy and Pictrs versions come out we will be performing the maintenance required to update during the maintenance periods listed above. If everything goes well with lemmy.ml's rollout (see here) we'll schedule a maintenance period. (I'm eyeing off the 8th of December currently)
Closing
Reddthat is constantly seeing new members sign-up though our new application process. Since implementing applications have gone from an abysmal 40% success rate to over a 90% success.
Welcome to all these new members and maybe today will be your first post or comment!
Cheers,
Tiff
On behalf of the Reddthat Admin Team.
17
Hello Reddthat,
Another month has flown by. It is now "Spooky Month". That time of year where you can buy copious amounts of chocolate and not get eyed off by the checkout clerks...
Lots has been happening at Reddthat over this last month. The biggest one being the new admin team!
New Administrators
Since our last update we have welcomed 4 new Administrators to our team! You might have seen them around answering questions, or posting their regular content. Mostly we have been working behind the scenes moderating, planning and streamlining a few this that 1 person cannot do all on their own.
I'd like to say: Thank you so much for helping us all out and hope you will continue contributing your time to Reddthat.
Kbin federated issues
Most of the time of our newly appointed admins have been taken up with moderating our federated space rather than the content on reddthat! As discussed in our main post (over here) https://reddthat.com/post/6334756 . We have chosen to remove specific kbin communities where the majority of spam was coming from. This was a tough decision but an unfortunate and necessary one.
We hope that it has not caused an issue for anyone. In the future once the relevant code has been updated and kbin federates their moderation actions, we will gladly 'unblock' those communities.
Funding Update & Future Server(s)
We are currently trucking along with 2 new recurring donators in our September month, bringing us to 34 unique donators! I have updated our donation and funding post with the names of our recurring donators.
With the upcoming changes with Lemmy and Pictrs it will give us the opportunity to investigate into being highly-available, where we run 2 sets of everything on 2 separate servers. Or scale out our picture services to allow for bigger pictures, and faster upload response times. Big times ahead regardless.
Upcoming Lemmy v0.19 Breaking Changes
Acouple of serious changes are coming in v0.19 that people need to be aware of. 2FA Reset and Instance level blocking per user
All 2FA will be effectivly nuked
This is a Lemmy specific issue where two factor authentication (2FA) has been inconsistent for a while. This will allow people who have 2FA and cannot get access to their account to login again. Unfortunately if someone outthere is successfully using 2FA then you will also need to go though the setup process again.
Instance blocks for users.
YaY!
No longer do you have to wait for the admins to defederate, now you will be able to block a whole instance from appearing in your feeds and comment threads. If you don't like a specific instance, you will be able to "defederate" yourself!
How this will work on the client side (via the web or applications) I am not too certain, but it is coming!
Thankyou
Thankyou again for all our amazing users and I hope you keep enjoying your Lemmy experiences!
Cheers
Tiff,
On behalf of the Reddthat Admin Team.

18
Hello Reddthat,
Similar to other Lemmy instances, we're facing significant amounts of spam originating from kbin.social users, mostly in kbin.social communities, or as kbin calls them, magazines.
Unfortunately, there are currently significant issues with the moderation of this spam.
While removal of spam in communities on other Lemmy instances (usually) federates to us and cleans it up, removal of spam in kbin magazines, such as those on kbin.social, is not currently properly federated to Lemmy instances.
In the last couple days, we've received an increased number of reports of spam in kbin.social magazines, of which a good chunk had already been removed on kbin.social, but these removals never federated to us.
While these reports are typically handled in a timely manner by our Reddthat Admin Team, as reports are also sent to the reporter's instance admins, we've done a more in-depth review of content in these kbin.social magazines.
Just today, we've banned and removed content from more than 50 kbin.social users, who had posted spam to kbin.social magazines within the last month.
Several other larger Lemmy instances, such as lemmy.world, lemmy.zip, and programming.dev have already decided to remove selected kbin.social magazines from their instances to deal with this.
As we also don't want to exclude interactions with other kbin users, we decided to only remove selected kbin.social magazines from Reddthat, with the intention to restore them once federation works properly.
By only removing communities with elevated spam volumes, this will not affect interactions between Lemmy users and kbin users outside of kbin magazines. kbin users are still able to participate in Reddthat and other Lemmy communities.
For now, the following kbin magazines have been removed from Reddthat:
[!random@kbin.social](/c/random@kbin.social)[!internet@kbin.social](/c/internet@kbin.social)[!fediverse@kbin.social](/c/fediverse@kbin.social)[!programming@kbin.social](/c/programming@kbin.social)[!science@kbin.social](/c/science@kbin.social)[!opensource@kbin.social](/c/opensource@kbin.social)
To get an idea of the spam to legitimate content ratio, here's some screenshots of posts sorted by New:
 ](
](
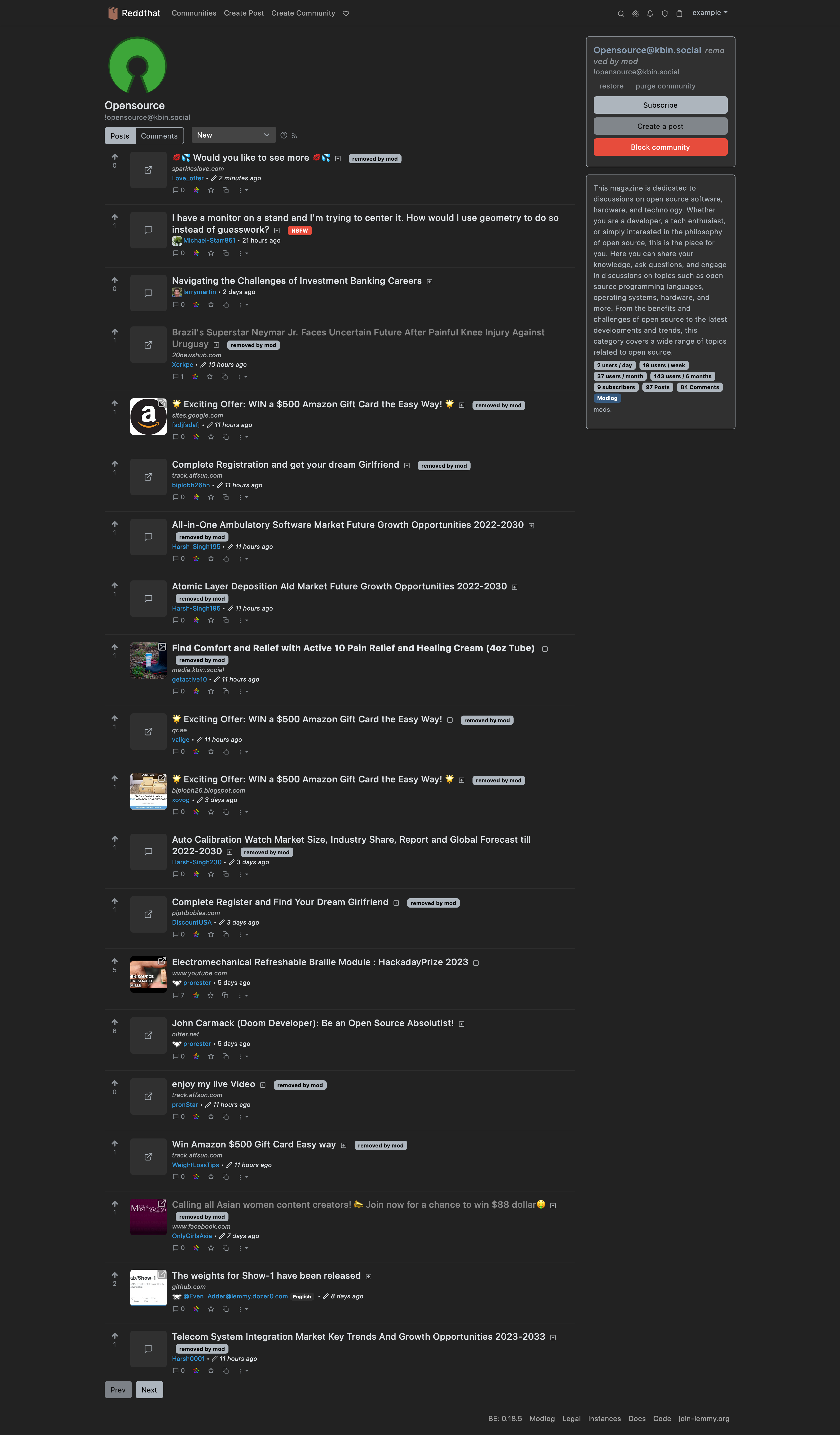 ](
](All the removed by mod posts mean that the content was removed by Reddthat admins, as the removals on kbin.social did not find their way to us.
If you encounter spam, please keep reporting it, so community mods and we admins can keep Reddthat clean.
If you're interested in the technical parts, you can find the associated kbin issue on Codeberg.
Regards,
example and the Reddthat Admin Team
TLDR
Due to spam and technical issues with the federation of spam removal from kbin, we've decided to remove selected kbin.social magazines (communities) until the situation improves.
19
Hello Reddthat,
It has been a while since I posted a general update, so here we go!
Slight content warning regarding this post. If you don't want to read depressing things, skip to # On a lighter note.
The week of issues
If you are not aware, the last week(s) or so has been a tough one for me & all other Lemmy admins. With recent attacks of users posting CSAM, a lot of us admins have been feeling a wealth of pressure.
Starting to be familiar with the local laws surrounding our instances as well as being completely underwhelmed with the Lemmy admin tools. All of these issues are a first for Lemmy and the tools do not exist in a way that enable us to respond fast enough or in a way in which content moderation can be effective.
If it happens on another instance it still affects everyone, as it effects every fediverse instance that you federate against.
As this made "Lemmy" news it resulted in Reddthat users asking valid questions on our !community@reddthat.com. I responded with the plan I have if we end up getting targeted for CSAM. At this point in time a user chose violence upon waking up and started to antagonise me for having a plan. This user is a known Lemmy Administrator of another instance. They instigated a GDPR request for their information. While I have no issue with their GDPR instigation, I have an issue with them being antagonising, abusive, and
Alternatively, stop attracting attention you fuckhead; a spineless admin saying “I’m Batman” is exactly how you get people to mess with you
Unfortunately they chose to create multiple accounts to abuse us further. This is not conduct that is conducive for conversation nor is it conduct fitting of a Lemmy admin either. As a result we have now de-federated from the instance under the control of that admin.
To combat bot signups, we have moved to using the registration approval system. The benefit to this system not only will ensure that we can hopefully weed out the bots and people who mean to do us harm, but we can use it to put the ideals and benefits of Reddthat in the forefront of the user.
This will hopefully help them understand what is and isn't acceptable conduct while they are on Reddthat.
On a lighter note
Stability
Server stability has been fixed by our hosting provider and a benefit is that we've been migrated to newer infrastructure. What this does for our vCPU is yet to be determined but we have benefited and have confirmed our status monitoring service (over here) is working perfectly and is detecting and alerting me.
Funding
Donations on a monthly basis are now completely covering our monthly costs! I can't thank you enough for these as it really does help keep the lights on.
In August we had 4 new donators, all recurring as well! Thank you so much!
Merch / Site Redesign
I would like to offer merchandise for those who want a hoody, mouse pad, stickers, etc.
Unfortunately I am a backend person, not a graphics designer. Thus if anyone would like to make some designs please let me know in the comments below. 🧡 An example:

I am thinking we need at least 3+ design choices:
- The Logo itself (Sticker/Phone/Magnet)
- Logo with Reddthat text
- Logo with
Where You've Truly 'ReddThat'! - Something cool that you would want on a hoody. <- Very important!
I've managed to find some on-demand printing services which will allow you to purchase directly through them and have it shipped directly from a local-ish printing facilities.
The goal is to reduce the time it takes you to get your merch, reduce the costs of shipping and hopefully ensure I know as little as possible about you as I can. If all goes to plan, I won't know about your addresses / payments / etc and everyone can have some cool merch!
New Admins
To help combat the spamming issue, the increase of reports and the new approval system I am looking for some new administrators to join the team.
While I do not expect you to do everything I do, an hour or two a day in your respective timezone, which amounts to randomly opening reddthat a couple times a day. Checking in to confirm everything is still hunky-dory is probably the minimum.
If you would like to apply to being an Admin to help us all out, please PM me with your approval answering the following questions:
Reason for your application:
Timezone:
Time you could allocate a day (estimate):
What you think you could bring to the team:
I am thinking we'll need about 6 admins to have full coverage around the globe and ensure that everyone will not be burnt out after a week! So even if you see a new admin pop up in the sidebar don't worry, there is always room for more!
Parting words
Thank you for those who have reached out and gave help. Thank you to the other Lemmy admins who helped me, and thank you everyone on Reddthat for still being here and enjoying our time together.
Cheers,
Tiff
tldr
- We have now defederated from our first instance :(
- Signups now are via Application process
- We had 4 new people join our recurring donations last month! 💛
- Merch is in the works. If you have some design skills please submit your designs in the comments!
- Admin recruitment drive

20
1
[Complete] Attack of the hardware monster, Reddthat's brief downtime 2023/08/31 - 2023/09/02
(reddthat.com)
Update: 2023/09/02:
This has now completed. Our host too extra time to migrate everything which caused a longer downtime than expected. (it was not an offline migration rather than a live migration).
If you were around during that time, you would have seen the status page & the incidents: https://status.reddthat.com/incident/254294
Cheers
Our hardware provider had an issue with our underlying host which caused the server to be powered off.
Pictured: Our hardware host becoming aware of the threat.
Unfortunately our server was not automatically powered on afterwards, or I jumped into the control portal too fast for the automatic start to work.
After starting our server we were back up and running.
Total downtime was ~5 minutes.
Next Steps
After a brief chat with our host, they have agreed to live migrate our VPS to another host over the coming week. This may cause a 10-30 second downtime if you even notice it.
Status Page
For all status related information don't forget we have a status page over here: https://status.reddthat.com which if we have anything longer than what we had today will be were I shall keep you all informed.
Thanks all!
Tiff
P.S. Video uploads work if they are small enough, both in length and size. Any video above 10 seconds won't work. This 8 second video is about the maximum our server can sustain currently.

21
14
Increased monitoring & video uploads... Why we had an issue with the site in the last hour(s)
(reddthat.com)
The things that I do while I'm meant to be sleeping is apparently break Reddthat! Sorry folks. Here's a postmortem on the issue.
What happened
I wanted a way in which I could view the metrics of our lemmy instance. This is a feature you need to turn on called Prometheus Metrics. This isn't a new thing for me, and I tackle these issues at $job daily.
After reading the documentation here on prometheus, it looks like it is a compile time-flag. Meaning the pre-build packages that are generated do not contain metric endpoints.
No worries I thought, I was already building the lemmy application and container successfully as part of getting our video support.
So I built a new container with the correct build flags, turned on my dev server again, deployed, and tested extensively.
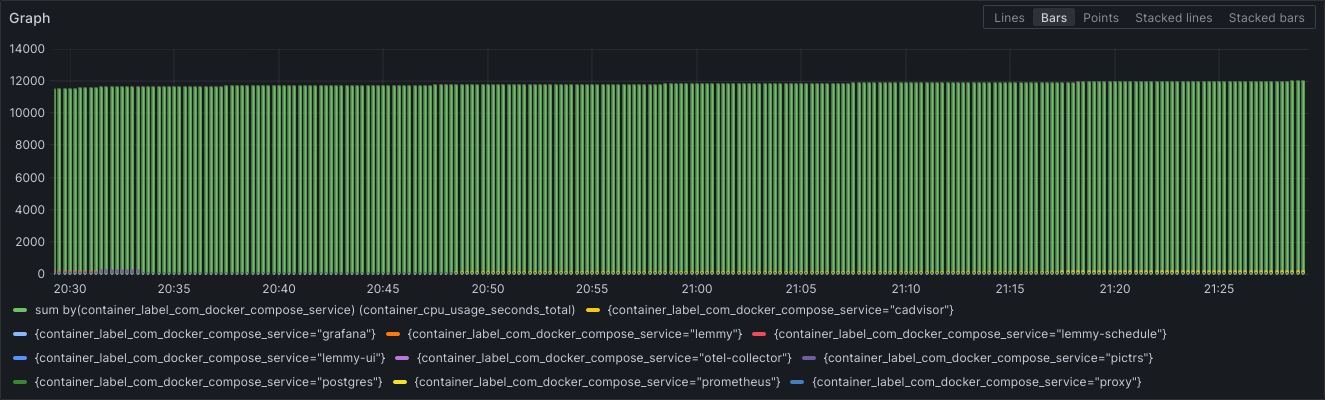
We now have interesting metrics for easy diagnosis. Tested posting comments, as well as uploading Images as well as testing out the new Video upload!
So we've done our best and deploy to prod.
ohno.webm
As you know from the other side... it didn't go to well.
After 2 minutes of huge latencies my phone lights up with a billion notifications so I know something isn't working... Initial indications showed super high cpu usage of the Lemmy containers (the one I newly created!) That was the first minor outage / high latencies around 630-7:00 UTC and we "fixed" it by rolling back the version, confirming everything was back to normal. I went and had a bite to eat.
not_again.mp4

Fool-heartedly I attempted it again, with: clearing out build cache, directly building on the server, more testing, more builds, more testing, and more testing.
I opened up 50 terminals and basically DOS'd the (my) dev server with GET and POST requests as an attempt to trigger some form of high enough load that it would cause the testing to be validated and I'd figure out where I had gone wrong in the first place.
Nothing would trigger the issue, so I continued along with my validation and "confirmed everything was working".
Final Issue

So we are deploying to production again but we know it might not go so well so we are doing everything we can to minimise the issues.
At this point we've completely ditched our video upload patch and gone with a completely blank 0.18.4 with the metrics build flag to minimise the possible issues.
NOPE

At this point I accept the downtime and attempt to work on a solution while in fire. (I would have added the everything-is-fine meme but we've already got a few here)
Things we know:
- My lemmy app build is not actioning requests fast enough
- The error relates to a Timeout happening inside lemmy which I assumed was to postgres because there was about ~15 postgres processes in the process of performing "Authentication" (this should be INSTANT)
- postgres logs show an error with concurrency.
- but this error doesnt happen with the dev's packaged app
- postgres isn't picking up the changes to the custom configuration
- was this always the case?!?!?!? are all the Lemmy admins stupid? Or are we all about to have a bad time
- The docker container
postgres:15-alpinenow points to a new SHA! So a new release happened, and it was auto updated. ~9 days ago.
So, i fsck'd with postgres for a bit, and attempted to get it to use our customPostgresql configuration. This was the cause of the complete ~5 minute downtime. I took down everything except postgres to perform a backup because at this point I wasn't too certain what was going to be the cause of the issue.
You can never have too many backups! You don't agree, lets have a civil discussion over espressos in the comments.
I bought postgres back up with the max_connections to what it should have been (it was at the default? 100). And prayed to a deity that would alienate the least amount of people from reddthat :P
To no avail. Even with our postgres sql tuning the lemmy container I build was not performing under load as well as the developers container.
So I pretty much wasted 3 hours of my life, and reverted everything back.
Results

- All lemmy builds are not equal. Idk what the dev's are doing but when you follow the docs one would hope to expect it to work. I'm probably missing something...
- Postgres released a new
15-alpinedocker container 9 days ago, pretty sure no-one noticed, but did it break our custom configuration? or was our custom configuration always busted? (with reference to thelemmy-ansiblerepo here ) - I need a way to replay logs from our production server against our dev environment to generate the correct amount of load to catch these edge cases. (Anyone know of anything?)
At this point I'm unsure of a way forward to create the lemmy containers in a way that will perform the same as the developers ones, so instead of being one of the first instances to be able to upload video content, we might have to settle for video content when it comes. I've been chatting with the pict-rs dev, and I think we are on the same page relating to a path forward. Should be some easy wins coming in the next versions.
Final Finally

I'll be choosing stability from now on.
Tiff
Notes for other lemmy admins / me for testing later: postgres:15-alpine:
2 months ago sha: sha256:696ffaadb338660eea62083440b46d40914b387b29fb1cb6661e060c8f576636
9 days ago sha: sha256:ab8fb914369ebea003697b7d81546c612f3e9026ac78502db79fcfee40a6d049
22
New UI Alternatives
After looking at our UI for a while I thought, someone will have created something special for Lemmy already. So I opened our development server, told it to get the bag rolling and investigated all the apps people have created.
Have a play around, all should be up and working. If there are other apps, ideas, or ways you think reddthat could be better please let me know!
Enjoy 😃
P.S. External UIs are a security issue
I would like to let everyone know that if you are using an external non-reddthat hosted UI (such as wefwef.app for example) you have given them access to full use of your account.
This happens because Lemmy checks for new notifications by performing GET requests via the api with the cookie in the URL field. https://instance/api/v3/user/unread_count?auth=your-authentication-cookie-here. This URL shows up in the logs of the third-party user interface. So if the third party was nefarious, they could look at their logs and get your cookie. Then they can login to your account or perform any requests.
So please only use the Reddthat user-interfaces as listed here & the main sidebar.
(If you are worried, you can log out of the thirdparty website, which will invalidate your cookie).
Tiff
https://old.reddthat.com

https://alexandrite.reddthat.com

https://photon.reddthat.com

https://voyager.reddthat.com

PS. I really like alexandrite.
23
24
25
view more: next ›