1
MorphMoe
244 readers
3 users here now
Anthropomorphized everyday objects etc. If it exists, someone has turned it into an anime-girl-or-guy.
- Posts must feature "morphmoe". Meaning non-sentient things turned into people.
- No nudity. Lewd art is fine, but mark it NSFW.
- If posting a more suggestive piece, or one with simply a lot of skin, consider still marking it NSFW.
- Include a link to the artist in post body, if you can.
- AI Generated content is not allowed.
- Positivity only. No shitting on the art, the artists, or the fans of the art/artist.
- Finally, all rules of the parent instance still apply, of course.
SauceNao can be used to effectively reverse search the creator of a piece, if you do not know it.
You may also leave the post body blanks or mention @saucechan@ani.social, in which case the bot will attempt to find and provide the source in a comment.
Find other anime communities which may interest you: Here
Other "moe" communities:
- !fitmoe@lemmy.world
- !murdermoe@lemmy.world
- !fangmoe@ani.social
- !cybermoe@ani.social
- !streetmoe@ani.social
- !midriffmoe@ani.social
- !kemonomoe@ani.social
- !officemoe@ani.social
- !meganemoe@ani.social
- !gothmoe@ani.social
- !militarymoe@ani.social
- !smolmoe@ani.social
founded 7 months ago
MODERATORS
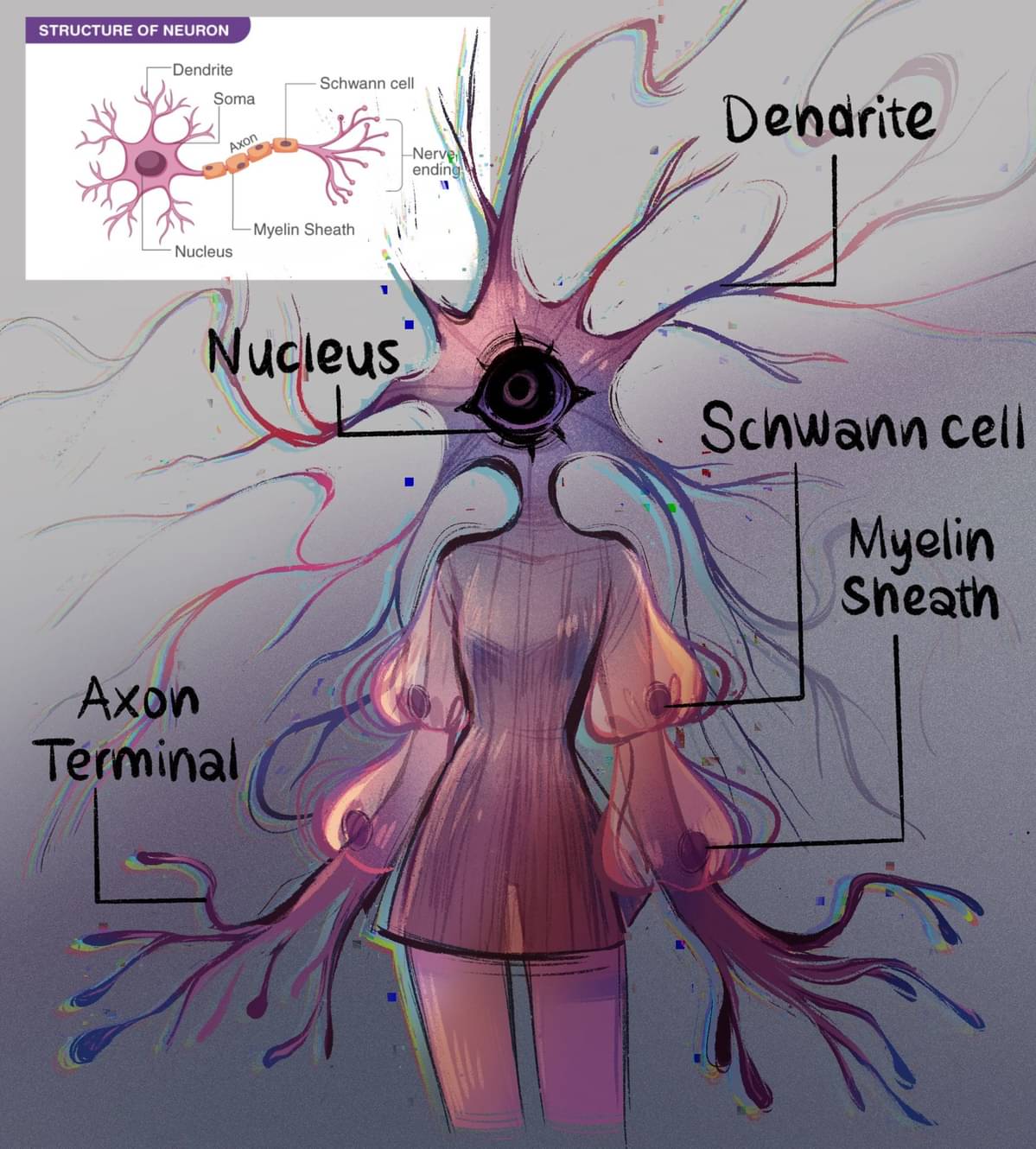
2

3
Artist: Onion-Oni aka TenTh from Random-tan Studio
Original post: #Humanization 19 on Tapas (warning: JS-heavy site)
Upscaled by waifu2x (model: upconv_7_anime_style_art_rgb). Original
Unlike photos, upscaling digital art with a well-trained algorithm will likely have little to no undesirable effect. Why? Well, the drawing originated as a series of brush strokes, fill areas, gradients etc. which could be represented in a vector format but are instead rendered on a pixel canvas. As long as no feature is smaller than 2 pixels, the Nyquist-Shannon sampling theorem effectively says that the original vector image can therefore be reconstructed losslessly. (This is not a fully accurate explanation, in practice algorithms need more pixels to make a good guess, especially if compression artifacts are present.) Suppose I gave you a low-res image of the flag of South Korea 🇰🇷 and asked you to manually upscale it for printing. Knowing that the flag has no small features so there is no need to guess for detail (this assumption does not hold for photos), you could redraw it with vector shapes that use the same colors and recreate every stroke and arc in the image, and then render them at an arbitrarily high resolution. AI upscalers trained on drawings somewhat imitate this process - not adding detail, just trying to represent the original with more pixels so that it loooks sharp on an HD screen. However, the original images are so low-res that artifacts are basically inevitable, which is why a link to the original is provided.

4
Artist: Onion-Oni aka TenTh from Random-tan Studio
Original post: #Humanization 19 on Tapas (warning: JS-heavy site)
Upscaled by waifu2x (model: upconv_7_anime_style_art_rgb). Original
I wonder where the beam would come from. The eyes?

5

6

7
Artist: Onion-Oni aka TenTh from Random-tan Studio
Original post: #Humanization 18 on Tapas (warning: JS-heavy site)
Upscaled by waifu2x (model: upconv_7_anime_style_art_rgb). Original
Finally, a MorphMoe waifu where I would figure out what the reference was.

8

9
Artist: Onion-Oni aka TenTh from Random-tan Studio
Original post: #Humanization 18 on Tapas (warning: JS-heavy site)
Upscaled by waifu2x (model: upconv_7_anime_style_art_rgb). Original
Unlike photos, upscaling digital art with a well-trained algorithm will likely have little to no undesirable effect. Why? Well, the drawing originated as a series of brush strokes, fill areas, gradients etc. which could be represented in a vector format but are instead rendered on a pixel canvas. As long as no feature is smaller than 2 pixels, the Nyquist-Shannon sampling theorem effectively says that the original vector image can therefore be reconstructed losslessly. (This is not a fully accurate explanation, in practice algorithms need more pixels to make a good guess, especially if compression artifacts are present.) Suppose I gave you a low-res image of the flag of South Korea 🇰🇷 and asked you to manually upscale it for printing. Knowing that the flag has no small features so there is no need to guess for detail (this assumption does not hold for photos), you could redraw it with vector shapes that use the same colors and recreate every stroke and arc in the image, and then render them at an arbitrarily high resolution. AI upscalers trained on drawings somewhat imitate this process - not adding detail, just trying to represent the original with more pixels so that it loooks sharp on an HD screen. However, the original images are so low-res that artifacts are basically inevitable, which is why a link to the original is provided.

10

11

12
Artist: Onion-Oni aka TenTh from Random-tan Studio
Original post: #Humanization 17 on Tapas (warning: JS-heavy site)
Upscaled by waifu2x (model: upconv_7_anime_style_art_rgb). Original

13

14

15
Artist: Onion-Oni aka TenTh from Random-tan Studio
Original post: #Humanization 17 on Tapas (warning: JS-heavy site)
Upscaled by waifu2x (model: upconv_7_anime_style_art_rgb). Original
Unlike photos, upscaling digital art with a well-trained algorithm will likely have little to no undesirable effect. Why? Well, the drawing originated as a series of brush strokes, fill areas, gradients etc. which could be represented in a vector format but are instead rendered on a pixel canvas. As long as no feature is smaller than 2 pixels, the Nyquist-Shannon sampling theorem effectively says that the original vector image can therefore be reconstructed losslessly. (This is not a fully accurate explanation, in practice algorithms need more pixels to make a good guess, especially if compression artifacts are present.) Suppose I gave you a low-res image of the flag of South Korea 🇰🇷 and asked you to manually upscale it for printing. Knowing that the flag has no small features so there is no need to guess for detail (this assumption does not hold for photos), you could redraw it with vector shapes that use the same colors and recreate every stroke and arc in the image, and then render them at an arbitrarily high resolution. AI upscalers trained on drawings somewhat imitate this process - not adding detail, just trying to represent the original with more pixels so that it loooks sharp on an HD screen. However, the original images are so low-res that artifacts are basically inevitable, which is why a link to the original is provided.

16
Artist: Onion-Oni aka TenTh from Random-tan Studio
Original post: #Humanization 16 on Tapas
I tried upscaled by waifu2x (model: upconv_7_anime_style_art_rgb) but it didn't go too well.

17


19

20

21
Artist: Onion-Oni aka TenTh from Random-tan Studio
Original post: #Humanization 16 on Tapas (warning: JS-heavy site)
Upscaled by waifu2x (model: upconv_7_anime_style_art_rgb). Original
Unlike photos, upscaling digital art with a well-trained algorithm will likely have little to no undesirable effect. Why? Well, the drawing originated as a series of brush strokes, fill areas, gradients etc. which could be represented in a vector format but are instead rendered on a pixel canvas. As long as no feature is smaller than 2 pixels, the Nyquist-Shannon sampling theorem effectively says that the original vector image can therefore be reconstructed losslessly. (This is not a fully accurate explanation, in practice algorithms need more pixels to make a good guess, especially if compression artifacts are present.) Suppose I gave you a low-res image of the flag of South Korea 🇰🇷 and asked you to manually upscale it for printing. Knowing that the flag has no small features so there is no need to guess for detail (this assumption does not hold for photos), you could redraw it with vector shapes that use the same colors and recreate every stroke and arc in the image, and then render them at an arbitrarily high resolution. AI upscalers trained on drawings somewhat imitate this process - not adding detail, just trying to represent the original with more pixels so that it loooks sharp on an HD screen. However, the original images are so low-res that artifacts are basically inevitable, which is why a link to the original is provided.

22
Artist: Onion-Oni aka TenTh from Random-tan Studio
Original post: #Humanization 15 on Tapas (warning: JS-heavy site)
Upscaled by waifu2x (model: upconv_7_anime_style_art_rgb). Original
Unlike photos, upscaling digital art with a well-trained algorithm will likely have little to no undesirable effect. Why? Well, the drawing originated as a series of brush strokes, fill areas, gradients etc. which could be represented in a vector format but are instead rendered on a pixel canvas. As long as no feature is smaller than 2 pixels, the Nyquist-Shannon sampling theorem effectively says that the original vector image can therefore be reconstructed losslessly. (This is not a fully accurate explanation, in practice algorithms need more pixels to make a good guess, especially if compression artifacts are present.) Suppose I gave you a low-res image of the flag of South Korea 🇰🇷 and asked you to manually upscale it for printing. Knowing that the flag has no small features so there is no need to guess for detail (this assumption does not hold for photos), you could redraw it with vector shapes that use the same colors and recreate every stroke and arc in the image, and then render them at an arbitrarily high resolution. AI upscalers trained on drawings somewhat imitate this process - not adding detail, just trying to represent the original with more pixels so that it loooks sharp on an HD screen. However, the original images are so low-res that artifacts are basically inevitable, which is why a link to the original is provided.

23
Artist: Onion-Oni aka TenTh from Random-tan Studio
Original post: #Humanization 15 on Tapas (warning: JS-heavy site)
Upscaled by waifu2x (model: upconv_7_anime_style_art_rgb). Original
Unlike photos, upscaling digital art with a well-trained algorithm will likely have little to no undesirable effect. Why? Well, the drawing originated as a series of brush strokes, fill areas, gradients etc. which could be represented in a vector format but are instead rendered on a pixel canvas. As long as no feature is smaller than 2 pixels, the Nyquist-Shannon sampling theorem effectively says that the original vector image can therefore be reconstructed losslessly. (This is not a fully accurate explanation, in practice algorithms need more pixels to make a good guess, especially if compression artifacts are present.) Suppose I gave you a low-res image of the flag of South Korea 🇰🇷 and asked you to manually upscale it for printing. Knowing that the flag has no small features so there is no need to guess for detail (this assumption does not hold for photos), you could redraw it with vector shapes that use the same colors and recreate every stroke and arc in the image, and then render them at an arbitrarily high resolution. AI upscalers trained on drawings somewhat imitate this process - not adding detail, just trying to represent the original with more pixels so that it loooks sharp on an HD screen. However, the original images are so low-res that artifacts are basically inevitable, which is why a link to the original is provided.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
25
Artist: Onion-Oni aka TenTh from Random-tan Studio
Original post: #Humanization 14 on Tapas (warning: JS-heavy site)
Upscaled by waifu2x (model: upconv_7_anime_style_art_rgb). Original
Unlike photos, upscaling digital art with a well-trained algorithm will likely have little to no undesirable effect. Why? Well, the drawing originated as a series of brush strokes, fill areas, gradients etc. which could be represented in a vector format but are instead rendered on a pixel canvas. As long as no feature is smaller than 2 pixels, the Nyquist-Shannon sampling theorem effectively says that the original vector image can therefore be reconstructed losslessly. (This is not a fully accurate explanation, in practice algorithms need more pixels to make a good guess, especially if compression artifacts are present.) Suppose I gave you a low-res image of the flag of South Korea 🇰🇷 and asked you to manually upscale it for printing. Knowing that the flag has no small features so there is no need to guess for detail (this assumption does not hold for photos), you could redraw it with vector shapes that use the same colors and recreate every stroke and arc in the image, and then render them at an arbitrarily high resolution. AI upscalers trained on drawings somewhat imitate this process - not adding detail, just trying to represent the original with more pixels so that it loooks sharp on an HD screen. However, the original images are so low-res that artifacts are basically inevitable, which is why a link to the original is provided.
{kind=link}

view more: next ›