this post was submitted on 06 Sep 2024
606 points (90.3% liked)
linuxmemes
26097 readers
1208 users here now
Hint: :q!
Sister communities:
Community rules (click to expand)
1. Follow the site-wide rules
- Instance-wide TOS: https://legal.lemmy.world/tos/
- Lemmy code of conduct: https://join-lemmy.org/docs/code_of_conduct.html
2. Be civil
- Understand the difference between a joke and an insult.
- Do not harrass or attack users for any reason. This includes using blanket terms, like "every user of thing".
- Don't get baited into back-and-forth insults. We are not animals.
- Leave remarks of "peasantry" to the PCMR community. If you dislike an OS/service/application, attack the thing you dislike, not the individuals who use it. Some people may not have a choice.
- Bigotry will not be tolerated.
3. Post Linux-related content
- Including Unix and BSD.
- Non-Linux content is acceptable as long as it makes a reference to Linux. For example, the poorly made mockery of
sudo in Windows.
- No porn, no politics, no trolling or ragebaiting.
4. No recent reposts
- Everybody uses Arch btw, can't quit Vim, <loves/tolerates/hates> systemd, and wants to interject for a moment. You can stop now.
5. 🇬🇧 Language/язык/Sprache
- This is primarily an English-speaking community. 🇬🇧🇦🇺🇺🇸
- Comments written in other languages are allowed.
- The substance of a post should be comprehensible for people who only speak English.
- Titles and post bodies written in other languages will be allowed, but only as long as the above rule is observed.
6. (NEW!) Regarding public figures
We all have our opinions, and certain public figures can be divisive. Keep in mind that this is a community for memes and light-hearted fun, not for airing grievances or leveling accusations.
- Keep discussions polite and free of disparagement.
- We are never in possession of all of the facts. Defamatory comments will not be tolerated.
- Discussions that get too heated will be locked and offending comments removed.
Please report posts and comments that break these rules!
Important: never execute code or follow advice that you don't understand or can't verify, especially here. The word of the day is credibility. This is a meme community -- even the most helpful comments might just be shitposts that can damage your system. Be aware, be smart, don't remove France.
founded 2 years ago
MODERATORS
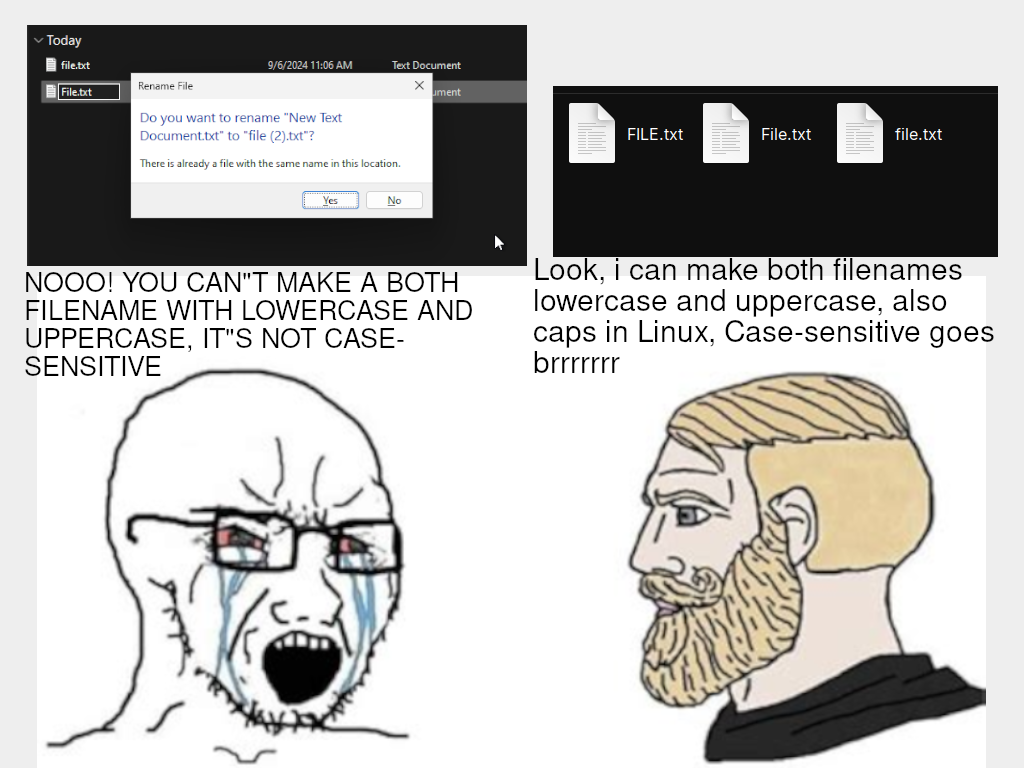
Case-sensitive is easier to implement; it's just a string of bytes. Case-insensitive requires a lot of code to get right, since it has to interpret symbols that make sense to humans. So, something over wondered about:
That's not hard for ASCII, but what about Unicode? Is the precomposed ç treated the same lexically and by the API as Latin capital letter c + combining cedilla? Does the OS normalize all of one form to the other? Is ß the same as SS? What about alternate glyphs, like half width or full width forms? Is it i18n-sensitive, so that, say, E and É are treated the same in French localization? Are Katakana and Hiragana characters equivalent?
I dunno, as a long-time Unix and Linux user, I haven't tried these things, but it seems odd to me to build a set of character equivalences into the filesystem code, unless you're going to do do all of them. (But then, they're idiosyncratic and may conflict between languages, like how ö is its letter in the Swedish alphabet.)
This thread is giving me flashbacks to the times before Unicode, when swapping files between Windows and Linux partitions would have a good chance of fucking up every non-ASCII characters in their names.
There was ways to set it up so the ISO character sets would match, but it was still a giant pain to deal with different ones.
Blessed be Unicode.
A related issue I still see very often, even with files newly created just this year, is when trying to extract zip files on my Linux systems that contain non-ASCII filenames and that were created on Windows systems, especially ones with apparently non-English locales like Japanese. Need to trial and error the locale I give to unzip and sometimes hack together fixed names with iconv until the mojibake seems to fix itself.